How LLMs Are Rewriting B2B Marketing Rules Nobody Saw Coming
Most B2B marketers are still optimizing for human researchers and last-click web analytics.
Meanwhile, an increasing share of early-stage discovery and shortlisting happens via LLMs that never show up in their attribution or dashboards.
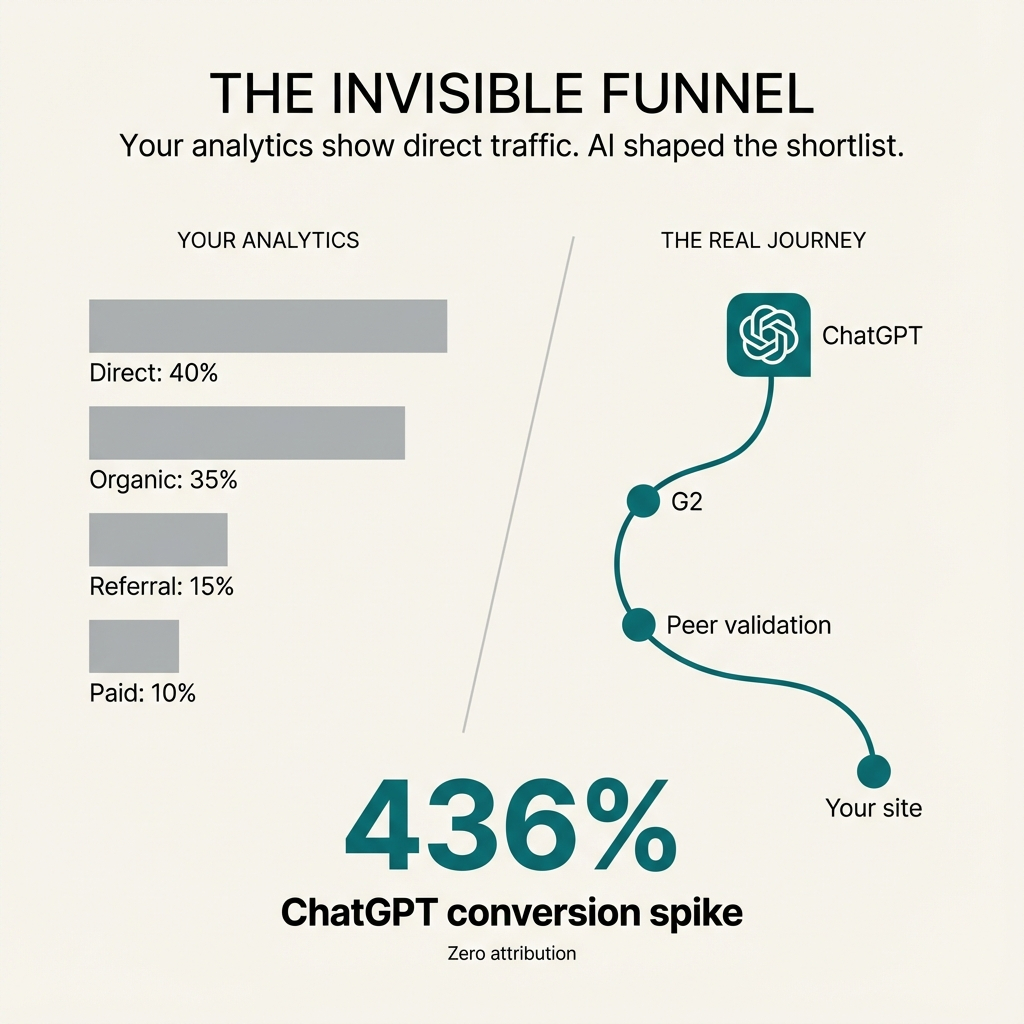
Buyers ask questions in ChatGPT, Perplexity, and Gemini. They get a synthesized shortlist. Then they show up as "direct" or "organic" traffic in your analytics.
You keep tuning websites and campaigns for the visible clicks. You're missing the upstream AI systems that actually shaped consideration.
The data is clear. One in four B2B buyers now use GenAI more often than conventional search when researching suppliers. Two-thirds rely on AI chatbots as much or more than Google or Bing when evaluating vendors.
In technology and software, 80% of buyers use AI tools as much or more than search engines. More than half—56%—rely on chatbots as a top source for vendor discovery.
Sales conversions driven by ChatGPT recommendations have skyrocketed by 436%.
Yet there's often zero attribution to the LLM mention. When someone discovers you through an LLM and visits later, it appears as direct traffic or typed URL that didn't pass referrer data.
The Attribution Gap You Can't See
Here's how a typical LLM-mediated journey actually unfolds.
A director of operations types into ChatGPT: "We're a 500-person healthcare company. What are the best SaaS tools to continuously monitor PHI exposure across Microsoft 365, Google Workspace, and Salesforce?"
They refine with follow-ups: "Focus on mid-market." "Must be HIPAA-aligned." "Compare pros and cons of each vendor."
The LLM builds and explains the shortlist.
The model returns a synthesized answer—a 4-6 vendor list with a short paragraph of strengths and weaknesses for each. Citations point to vendor docs, review sites, and analyst content.
If your public footprint is thin, inconsistent, or missing from trusted sources like G2 or analyst blogs, you either don't appear at all or show up as a generic "also-consider" with weak positioning.
The buyer validates with humans and web searches. For vendors the LLM surfaced, most buyers go straight to the vendor website to check fit. They open a couple of review tabs—G2, Reddit, industry forums.
In your analytics, this looks like direct or organic visits. Some referral from review sites. Maybe branded search.
No trace that ChatGPT did the heavy lifting to generate the initial list.
They narrow via peers, then come back to you. The buyer takes 2-3 LLM-suggested vendors to colleagues or internal Slack: "Anyone used X vs Y for PHI monitoring in Google Workspace?"
Based on feedback, they come back to 1-2 sites, read pricing and docs, and fill out a demo form.
In Salesforce or HubSpot, the opportunity gets tagged as "Source: Direct / Organic Search / Web form."
The LLM never appears in the chain.
What Makes Content LLM-Ready
An LLM-ready footprint is built so a machine can confidently answer "who are you, who do you serve, what do you do, and how do you compare?" without guessing.
Traditional SEO is about ranking pages for queries. LLM-readiness is about making your whole public presence extractable, unambiguous, and consistent so models can safely put you in their answers.
Answer-first formatting matters.
Clear, one-sentence definitions at the top of pages work. "Product X is a SaaS security platform that does Y for Z segment."
Sections that directly answer likely prompts help. "Who is this for?" "What problems does it solve?" "Key limitations." "Alternatives to Product X."
FAQ and comparison sections with explicit question-style headings perform well. "Is Product X HIPAA compliant?" "Product X vs Competitor Y for healthcare SaaS posture."
Short, self-contained answers under each question mean the model can lift them without heavy rewriting.
This makes your content ready-made for summarizing instead of forcing the model to infer your positioning from scattered snippets.
Consistent entity data everywhere is critical.
Same product and company names, category labels, ICP description, and key feature language across your site, docs, profiles, and marketplaces.
No conflicting taglines like "SaaS security platform" in one place and "cloud backup vendor" in another. Inconsistency weakens the model's confidence about what you actually are.
JSON-LD schema with accurate names, descriptions, and relationships to categories and use cases helps. Clear metadata (author, publish dates, update dates, and references) matters because LLM-search systems use these as authority and freshness signals.
This helps models reliably bind "Your Brand = this category, this ICP, these core capabilities" and reduces the odds you appear as a fuzzy, generic mention.
Why Objectivity Became Trust Currency
LLMs don't prefer neutral tone because it's polite.
They prefer objective, constraint-aware content because it's easier to verify, cross-check, and safely recombine without hallucinating.
That makes objective content a kind of trust currency. It lowers the model's risk of being wrong, so the model is more likely to use and cite you.
LLMs are trained and tuned to avoid confidently false statements, especially in domains like B2B and compliance. When your content contains specific, checkable facts (who you serve, what you do, limits, trade-offs), it can be cross-validated against docs, reviews, and other sites.
Over-hyped or vague claims like "best in class" or "revolutionary" don't map cleanly to external evidence. They contribute less to the model's confidence and are often down-weighted or ignored in favor of more concrete sources.
Objective content defines scope and constraints. "We support these use cases, not those." "Works for X to Y segment; less suited for Z."
This helps the model know when you are not the right answer.
That boundary-setting is valuable because LLMs are optimized to give appropriate answers to specific prompts. If your content admits limits, the model can match you more precisely to the right scenarios instead of diluting you into generic noise.
The implication isn't "be bland."
It's "be decisive and specific, but grounded."
Clearly state who you are best for and why, using concrete criteria (company size, stack, industry, regulatory context) and where possible, quantified outcomes.
Example: "We help mid-market healthcare and fintech teams monitor SaaS posture across M365, Google Workspace, and Salesforce with continuous misconfiguration detection and automated response, typically reducing open critical findings by 30-40% in the first 6 months."
Spell out "ideal fit" and "not ideal" cases in your own materials. "Best suited for orgs with centralized IT and SSO; less suited to small teams running purely on local desktops."
This feels risky in traditional marketing. For LLMs it's a strong positive signal. It clarifies when to recommend you and when not to, which increases the chance you are chosen when the prompt matches your sweet spot.
In an LLM-mediated world, objectivity doesn't mean sounding like a regulator. It means giving the model enough grounded, self-aware signal that it can recommend you without feeling like it's lying.
The companies that win are the ones whose positioning is sharp and framed in language an AI can safely stand behind in front of a skeptical buyer.
Authority as Machine-Verifiable Expertise
"Authority as a Service" used to mean publish smart opinions everywhere so humans see your logo often enough to assume you're credible.
In an LLM-mediated world, that's not enough.
Authority now has to be machine-verifiable expertise. Content and signals that an LLM can cross-check, triangulate, and safely reuse as the backbone of its own answers.
For LLMs, authority is less about charisma and more about discoverable credibility.
Models look for the same claims and topics attached to your brand across multiple accessible sources: your site, docs, analyst mentions, reviews, communities. When they align, the model can treat you as a reliable entity for that domain.
Authority rises when your content offers specific, checkable statements (who you serve, what you do, where it works and doesn't) that agree with third-party descriptions. This lowers hallucination risk, so your material is more likely to be incorporated directly into answers.
Analyst, review, and community content still matter, but only when LLMs can actually see it.
Firms and vendors that keep insights behind paywalls retain human prestige but lose algorithmic authority because GenAI systems can't ingest or cite them.
The model "trusts" you when it can see you across multiple credible surfaces and detect that your claims are bounded, factual, and aligned with what others say.
This shifts Authority-as-a-Service from "we'll make you look smart everywhere" to "we'll make your expertise machine-legible and cross-validated."
Thought leadership still matters, but it has to produce artifacts that LLMs can reuse as references. Clearly structured explainers, frameworks, and benchmarks with explicit scope and limits work better than provocative opinion pieces.
You don't just chase bylines. You ensure that key ideas, definitions, and claims about your domain show up consistently in open analyst summaries, peer review platforms like G2 and Gartner Peer Insights, and community venues like Reddit and industry forums that GenAI often cites.
LLMs reward depth and coherence more than volume. It's better to be the clearly documented expert on "continuous SaaS posture for regulated industries" than to publish generic security hot takes across 20 topics.
Topic consistency is what teaches models "this brand = this problem space."
The Gated Content Trade-Off
The trade-off is no longer "leads vs free content."
It's short-term lead capture vs long-term inclusion in the AI layer that now shapes your entire pipeline.
If your best material is invisible to LLMs, you may optimize form fills while quietly losing category visibility and consideration.
Gated mid and bottom-funnel assets still convert visitors to leads at materially higher rates than ungated versions. They can generate 20 to 30% better lead-to-customer conversion in many B2B tests. Gating also makes attribution and nurturing easier. You know exactly who consumed which asset and can align outreach and sequences.
But fully gated assets generate dramatically less organic and AI-driven visibility.
One 2025 study found fully gated content drove roughly 82% less organic traffic and was cited roughly 94% less often by AI systems than comparable open content.
Invisible content earns zero authority. If LLMs and AI search cannot crawl or reference your deepest insights, they can't use them to recommend you or cite you in answers.
The decision isn't "gate or not." It's where do you accept friction, and where do you need maximum machine-and-human reach because that's what gets you into the consideration set at all.
Here's a sensible calculus many leading B2B teams are moving toward.
Ungate or partially ungate anything that defines your category authority. Problem definitions, frameworks, benchmarks, and core case studies that prove you understand the space need to be visible and crawlable. Those are exactly what LLMs use to answer "who are the credible players in X?"
If you must gate, use hybrid patterns. Enough of the content or a detailed summary lives in HTML on the page so AI crawlers can index and learn from it, while the downloadable or extras sit behind a form.
Reserve hard gates for high-intent, implementation-level content. Late-stage assets that map directly to "how to buy or implement" (RFP templates, migration playbooks, in-depth ROI models) are still strong candidates for gating because they signal real evaluation and are less critical for broad algorithmic authority.
Even there, make sure the page that hosts them clearly describes what's inside in indexable text. LLMs can still reference the existence and gist of the asset, even if the PDF itself is gated.
Add KPIs like mentions or citations in AI overviews, inclusion frequency when testing relevant prompts, and AI-driven traffic patterns alongside traditional MQL and SQL metrics.
When ungating or hybrid-gating a flagship asset, watch whether direct and organic demo requests from net-new accounts increase and whether AI tools start summarizing or citing your work in answers about your category.
The mental model that helps: Gates are for capturing demand you already earned.
Ungated, crawlable expertise is what earns you a seat in the AI-mediated discovery layer in the first place.
What Discoverability Means Now
Discoverability now means "how often and how well you show up inside answers" instead of "where you rank in a list of links."
In an LLM-mediated world, you measure whether you're discoverable by tracking your representation in AI outputs—presence, prominence, context, and accuracy across the prompts your buyers actually use.
Instead of "Are we on page 1 for this keyword?" the core questions become different.
"When someone asks an AI assistant about our problem space, do we appear in the answer at all?"
"If we appear, how are we framed—as a primary recommendation, a supporting mention, or a footnote?"
"Across tools like ChatGPT, Gemini, Perplexity, and AI Overviews, are we recognized consistently for the same category and strengths, or does our story change?"
Discoverability is the combination of being included, being prominent, and being correctly understood by both humans and AI systems.
Teams that are taking AI visibility seriously use a new set of metrics.
Coverage: For a defined set of category and use-case prompts, what percentage of AI answers mention your brand at all? This is the AI-era analogue of "are we on page 1?"
Frequency and share of voice: How often your brand is cited across many prompt variations vs key competitors—an "AI share of voice" curve over time. If competitors' mention frequency is rising while yours is flat, you are losing discoverability even if web traffic looks stable.
Placement and authority weight: Whether you appear as a definitive source, a primary recommendation in a short vendor list, or one of many undifferentiated mentions. Some frameworks score this to produce an "AI authority weight" metric month over month.
Accuracy and sentiment: Are your category, capabilities, and ICP described correctly, or is the AI mixing you up with the wrong space or outdated positioning? Is the overall tone favorable, neutral, or negative when you are referenced?
In practice, measuring discoverability means defining a set of prompts that mirror how your ICP actually asks questions by problem, industry, size, and stack. Regularly sample AI responses across major platforms and log brand mentions, position, co-mentioned competitors, and framing.
Turn those into a small dashboard: AI coverage, AI share of voice, AI authority weight, AI accuracy and sentiment.
If those lines are moving up and to the right while staying accurate, you are becoming more discoverable in the environment that now shapes how buyers shortcut from prompt to shortlist.
If they're flat or declining, it doesn't matter how strong your traditional SEO looks. You are gradually disappearing from the answer layer where the modern B2B journey increasingly begins.
Just five brands appear in 80% of top responses delivered by AI agents across any given B2B category.
Supplier visibility is becoming binary. Either a brand is recommended by AI or it is not found at all.
How Sales Cycles Compress
When you show up correctly in an LLM answer, the buyer doesn't just "become aware" of you.
They often arrive at your front door pre-framed, pre-qualified, and partially de-risked in their own mind.
That's what compresses the sales cycle. Most of the messy, early work of defining the problem, scanning the market, and eliminating bad fits has already happened before your team ever speaks to them.
LLMs and AI search are increasingly handling three parts of the journey that used to consume weeks of back-and-forth.
Buyers use AI to clarify what their problem actually is, what good looks like, and what requirements they should care about. They show up to you with a shared internal vocabulary and a first-pass RFP or checklist largely generated by AI.
AI tools pull from your site, reviews, and analyst content to build a shortlist that already matches basic fit criteria (industry, size, use cases, compliance context). If your content is LLM-ready and objective, you're recommended for the right scenarios, which means the buyers who contact you are more likely to be in your target ICP.
LLMs can highlight typical pros and cons, known limitations, and integration caveats, often pulling from third-party sources. That gives buyers a baseline sense of "where this vendor shines and where they might not fit," which reduces perceived personal risk in advocating for you.
By the time someone hits "Book a demo," a significant chunk of what used to be Stage 1 to 2 discovery and education is already done, with you positioned as a plausible, vetted option.
In organizations seeing measurable cycle compression from AI-referred prospects, a few consistent patterns show up in calls and emails.
Reps report spending far less of the first call on basic intro slides. Buyers often say things like "We've already compared you to X and Y. Here's what we think you're better at, and here's what worries us."
That lets sales move quickly into tailoring, architecture, and objections instead of running a generic pitch.
Because the AI shortlist already filtered by industry, use case, and key requirements, a greater share of inbound opportunities match your ideal customer profile. That reduces time lost on misfit deals where weeks go by before someone finally admits "this isn't actually the right solution for our stack or risk profile."
Buyers arrive with AI-drafted questions. "How exactly do you handle SaaS-to-SaaS OAuth relationships?" "Can you show how your SSPM logic maps to HIPAA audit requirements?"
When the first meeting starts at that depth, the path to technical validation, security review, and commercial negotiation is shorter because you're not climbing from zero context.
Research shows that when buyers use AI to generate and refine a shortlist, they talk to fewer vendors but spend more time with each finalist. If an LLM frames you as a top 2-3 fit for a very specific scenario, you're more likely to be one of those deeper conversations and less likely to be part of a 10-vendor bake-off.
Internal stakeholders also use AI to answer "what does this category do?" and "what should we look for?" reducing time spent educating non-technical or non-security stakeholders. That shortens the committee-education phase, which is often where weeks are lost in complex B2B deals.
When multiple independent sources (LLMs, review sites, peers) all converge on a similar description of you, the buying group's perceived risk is lower from day one. Lower perceived risk means fewer "let's add two more vendors just in case" detours and less need for repeated reassurance cycles.
Early case studies are showing 20 to 30% reductions in cycle length when AI is used for pre-qualification and lead preparation.
Reps spend their time on already-aligned prospects rather than on basic education and disqualification.
What Breaks First in Your Organization
What breaks first is the entire "marketing throws MQLs over the wall" machinery: specifically lead scoring, SDR workflows, and the rigid MQL to SQL handoff.
AI-educated buyers don't need that much shepherding, so those systems start generating friction and false negatives instead of accelerating deals.
Lead scoring models are usually tuned for "did they download our eBook, attend our webinar, or visit pricing 3 times?" They're not tuned for "did they arrive with a clear AI-informed problem, shortlist, and timeline?"
High-intent, AI-educated buyers often do fewer legacy "engagement" actions because they already did their homework elsewhere. They look colder in the model than they actually are and get routed too slowly or to the wrong tier.
SDR scripts are built to ask basic discovery questions and deliver a canned pitch. AI-educated buyers show up wanting to validate specifics, not hear "what we do" from scratch.
This makes SDR outreach feel redundant or even annoying. Buyers have already self-qualified via AI and peers, and now have to repeat context to a gatekeeper who can't go deep. Conversion drops, and cycles lengthen.
Funnels assume a clean progression: MQL to SAL to SQL. In reality, AI-enabled buyers bounce between stages, updating requirements, testing alternatives, and coming back with new questions. Handoffs tuned for linear funnels miss the moment when the buyer is actually ready to move or force them through unnecessary steps "because that's our process."
Teams that are adapting are converging on three big shifts.
Marketing, sales, and success operate as a shared revenue team focused on opportunities and accounts, not just lead volume. Marketing owns LLM visibility, education content, and pre-sale digital experience instead of just top-of-funnel form fills. AEs or senior consultative sellers get involved earlier for qualified inbound because those buyers are already mid-journey when they show up. Success and solutions architects feed usage patterns and objections back into content and AI-facing assets so the AI layer learns your real strengths and constraints.
The SDR role doesn't disappear, but it shifts from "mini-seller who re-qualifies everything" to signal router and conversation enabler. SDRs use AI and intent data to enrich inbound interest—who they are, what they've likely already learned, what prompts and use cases they care about. They route high-intent, AI-educated buyers directly to the right expert as fast as possible, often with tighter SLAs and fewer hoops. They handle lower-intent or ambiguous leads with async channels like email, chat, or product tours rather than insisting on a full discovery call.
Scoring and routing need to reflect the new reality. Introduce an AQL or AI-qualified account concept: leads and accounts that arrive with strong fit signals and behaviors consistent with AI-mediated research. These skip some of the old MQL hoops and get prioritized routing to senior reps. Shift from single-lead scoring to account-level intelligence. Aggregate signals like multiple stakeholders reading solution docs, security pages, and comparison content over a short period, or repeat branded visits following spikes in AI search traffic. Use that to trigger coordinated outreach from sales and success instead of just a nurture sequence.
In the restructured model, high-intent inbound goes straight to an expert with full context, often within hours, and the first call sounds like a second or third meeting from the old world. SDR and BDR ops focus on cleaning and routing signal, not interrogating buyers. Low-intent leads are handled asynchronously and cheaply. Marketing reports on AI discoverability metrics, AQL volume, and opportunity velocity instead of just MQL counts.
The thing that breaks first is the assembly-line assumption.
That buyers need to be slowly walked through education and qualification by separate teams.
In an LLM-mediated world, the org that wins is structured around specialists who can meet already-informed buyers in smarter conversations quickly, with ops and AI doing most of the pre-work in the background.
The One Move to Make This Quarter
The safest high-leverage first move is not to rewrite your entire org chart.
Run one tightly scoped pilot where you change how you handle a specific slice of inbound AI-educated demand and measure the impact at the opportunity level, not the MQL level.
Carve out a controlled lane and prove "this works better" before you touch compensation or core funnel definitions.
Design a 60 to 90 day experiment for a narrow but important band of inbound leads (for example, mid-market healthcare and fintech inbound with clear SaaS security interest) with three concrete changes.
Define simple AQL criteria for the pilot: ICP fit plus key behavioral signals like pricing, solution, or security pages visited, specific form questions, or referral notes that suggest they've already done AI-mediated research. For those leads and accounts, bypass parts of the old process (no SDR discovery gate, or a very light async touch) and route straight to a senior AE or SE pod with a tight SLA.
Enable that AE or SE pod with a different brief. Assume the buyer already knows the basics and structure first calls around validation and tailoring ("Here's where we're strong and weak for your exact scenario") instead of the generic deck. Capture a few standard fields after each call: stage reached, decision drivers, and "how did you research before talking to us?" to validate that you're actually seeing the AI-educated segment.
For the pilot lane, ignore MQL volume as the success metric. Track opportunity creation rate from inbound, time from first touch to opportunity, and win rate and sales cycle length vs a control group still going through the classic MQL to SDR to AE path. The goal is to show that this fast lane produces equal or better pipeline with shorter time-to-opportunity and higher conversion, using existing people and tools.
You're not abolishing MQLs or SDRs.
You're carving out a small, clearly instrumented exception path and treating it as a live A/B test. SDRs stay intact but act more as enrichers and routers for the pilot lane while still running the traditional playbook for the rest of the funnel. Comp doesn't have to change immediately. You can credit pipeline and revenue from the pilot lane the same way you do today while you gather evidence.
If that pilot shows what many early adopters are already seeing (faster opportunity creation, better win rates, and fewer wasted calls with already-informed buyers), then you have the internal proof to evolve scoring toward AQL and MQA and away from pure MQL volume, redefine SDR roles around routing and account intelligence rather than re-education, and gradually restructure teams into revenue pods without asking the organization to "take it on faith."
Stand up a narrowly scoped AI-educated inbound fast lane with its own routing and measurement. That gives you real data on the future model while the old machine keeps running beside it. It turns the structural shift from a philosophical debate into a pipeline conversation.
The Core Mental Model That Needs to Change
The core misunderstanding is that most B2B organizations still think they are the ones running the journey.
In reality, the journey is now an AI-mediated network of decisions where buyers—and their tools—are in control, and vendors are just one set of inputs into that system.
The old mental model assumed the funnel is linear and seller-centric. Marketing generates demand, sales "takes buyers through" stages, content is bait to pull people into your owned channels. Authority is something you broadcast: more content, more events, more visibility eventually create trust.
The new mental model recognizes the journey is buyer-led and AI-orchestrated.
Buyers loop between LLMs, search, peers, review sites, and your properties, using AI to frame the problem, shortlist vendors, and pre-qualify options before you ever see them.
Authority is something you must earn inside a system you do not control. LLMs, algorithms, and communities cross-check your claims against others and decide when you show up, how you're framed, and in which contexts.
That means the job is no longer to "move people down our funnel" but to feed and shape a larger decision network so that when buyers and their AI agents run the loop, you are present in the right questions, represented accurately and specifically, and recommended for the scenarios where you're truly the best fit.
Until that mental model shifts (from "we own the funnel" to "we optimize our role in an AI-mediated, buyer-controlled system"), everything else will be incremental tweaks on a structure that no longer matches how decisions are actually made.
The One Piece of Advice That Matters
Treat AI-mediated buyers as the new default, not an edge case.
Start running your entire go-to-market as if most serious prospects will meet you through an assistant first and your team second.
That mindset shift does two practical things that separate the thriving organizations from the ones stuck optimizing a dying model.
It forces every decision to start from a new question: "If a buyer's AI assistant were advising them on this problem, would it know we exist? Would it understand exactly where we're a fit and where we're not? Would it have enough objective, consistent evidence to recommend us with confidence?"
It pushes you to invest first in making your expertise machine-legible and buyer-legible, then in reorganizing humans around smarter, later-stage conversations instead of squeezing a few more points out of MQL volume.
The organizations that will thrive are the ones that stop asking "How do we get more people into our funnel?" and start asking, every quarter: "How do we become the safest, clearest recommendation an AI (and a skeptical buying committee behind it) can make for this specific problem?"
Everything else flows from that.



Comments
Post a Comment